
Amazon Review Data Classifier
Objective
To develop machine learning code that analyzes reviews of certain types of product on Amazon and come up with a method to predict whether a product as
“good” or “not good”.
Data
We were given two files:
Training.csv: This file is a CSV file consisting of review-related information with fields: Reviewer ID, Amazon ID, Number of votes on the review, Number of votes that said the review was helpful, Time of review, Review Text, Summary, Price of albums, Genres, Binary variable denoting if the product is “good” or “not good”.
Test.csv: This file contains all the same features but the last binary variable.
Tried Approaches
We explored training our model on different features and using different classifiers. Included are two tables summarizing the performances of all the approaches we tried.
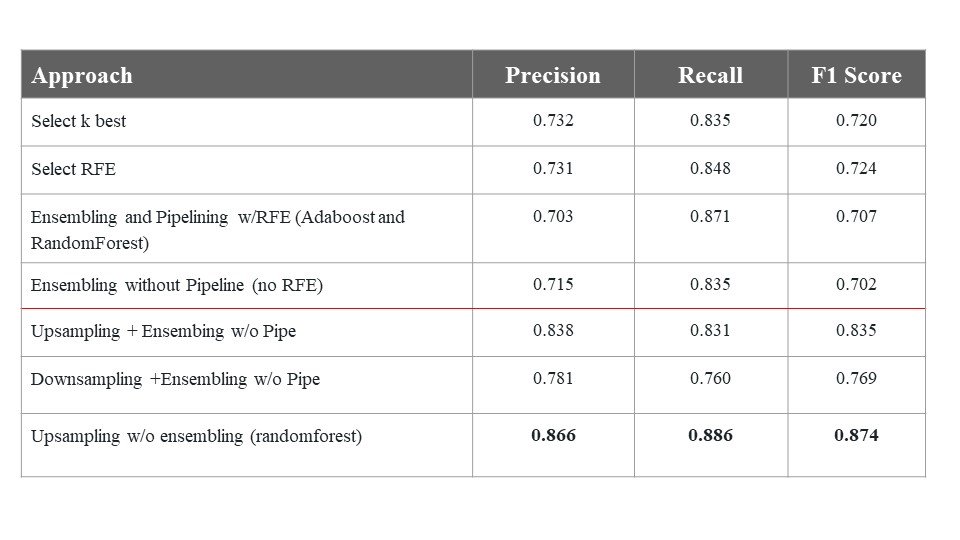
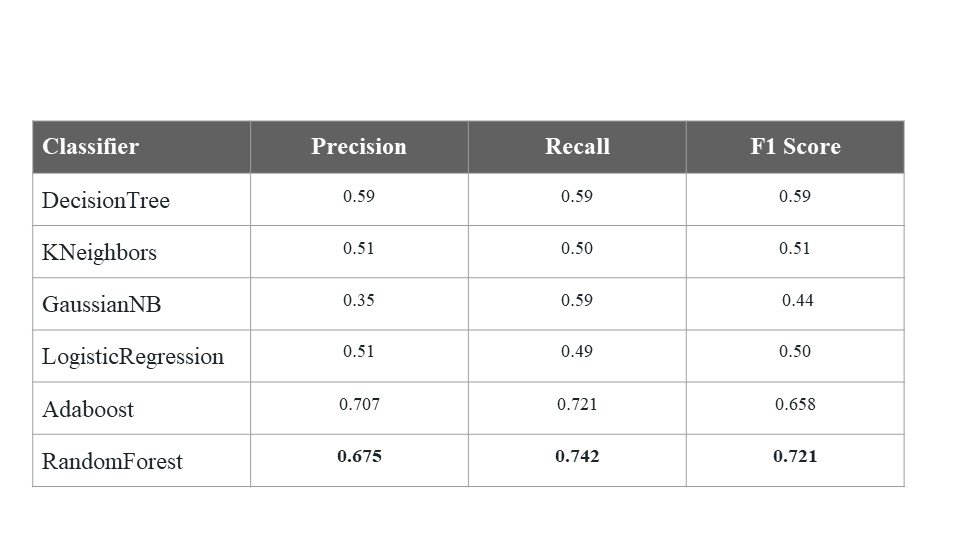
Final Approach
We ultimately decided on training our model on the following features: TFIDF vectorizer bi and unigram features, reviewText sentiment polarity, summary sentiment polarity, helpful ratio, artist, salesrank. We also used the RandomForest classifier with hyperparameter optimization using GridSearchCV and 10-Fold Cross Validation after upsampling the not good class. This gave us a very high precision value, recall, and f1 score.

Feel free to check the slides to go over approaches that did not work and the final code on my Github.